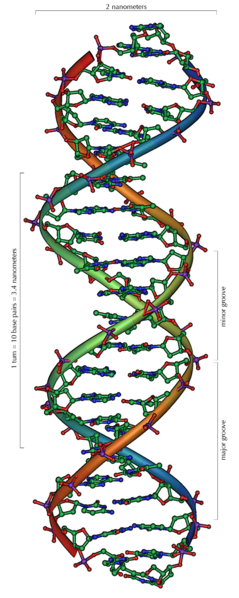
DNA는 'Deoxyribonucleic acid'의 줄임말로, 현재 알려진 모든 생명체와 일부 바이러스에서 발생과 기능을 위해 이용되는 유전적 명령을 담고있는 '핵산' 입니다. DNA 분자의 주요 역할은 정보를 장기간 저장하는 것입니다. DNA는 단백질과 RNA분자와 같은 세포의 구성요소를 형성하는데 필요한 명령을 갖고있기 때문에, 종종 청사진이나 조리법과 비교됩니다. DNA 조각은 유전자라 부르는 유전 정보를 운반합니다. 그러나 다른 DNA 서열은 구조적인 목적이나 유전 정보의 사용을 조절하기 위해서 존재합니다.
화학적으로, DNA는 당(sugar)으로 구성된 뼈대와 에스테르 결합으로 결합하고 있는 인산기(phosphate group), 그리고 뉴클레오티드(nucleotide)라 부르는 간단한 단위의 긴 중합체(polymer) 두개로 구성됩니다. 이들 두 사슬은 서로 반대방향으로 진행하기 때문에 역평행(anti-parallel)이라고 합니다. 각 당에는 염기(base)라 부르는 4종류의 분자중 하나가 붙어 있습니다. 뼈대를 따라 있는 이들 네 종류 염기의 순서가 정보를 암호화합니다. 이 정보는 단백질 내의 아미노산 순서를 정하는 유전적 코드를 사용해 읽게 됩니다. 코드는 DNA에서 관련된 핵산 RNA로 복사됨으로써 읽혀지고, 이 과정을 전사(transcription)라고 합니다.
세포 내에서, DNA는 염색체(chromosomes)라 부르는 구조로 조직화되어 있습니다. 이들 염색체는 세포가 분열하기 전에 DNA 복제(replication)이라는 과정에 의해서 두배로 복제됩니다. 진핵생물(Eucaryotic organisms, 동물.식물.균류)은 세포 핵 안에 DNA를 저장하지만, 원핵생물(Prokaryotes, 박테리아. 시원생물)은 세포의 세포질(cytoplasm)에서 발견됩니다. 염색체 내에서, 히스톤(histone)과 같은 염색질(chromatin)단백질 이 DNA를 밀집하고 조직화합니다. 이러한 밀집 구조는 DNA와 다른 단백질 사이의 상호작용을 안내하고, DNA 일부분의 전사 조절을 도와줍니다.
In chain terminator sequencing (Sanger sequencing), extension is
initiated at a specific site on the template DNA by using a short
oligonucleotide 'primer' complementary to the template at that region.
The oligonucleotide primer is extended using a DNA polymerase,
an enzyme that replicates DNA. Included with the primer and DNA
polymerase are the four deoxynucleotide bases (DNA building blocks),
along with a low concentration of a chain terminating nucleotide (most
commonly a di-deoxynucleotide). Limited incorporation of the
chain terminating nucleotide by the DNA polymerase results in a series
of related DNA fragments that are terminated only at positions where
that particular nucleotide is used. The fragments are then
size-separated by electrophoresis in a slab polyacrylamide gel, or more
commonly now, in a narrow glass tube (capillary) filled with a viscous
polymer.
An alternative to the labelling of the primer is to label the
terminators instead, commonly called 'dye terminator sequencing'. The
major advantage of this approach is the complete sequencing set can be
performed in a single reaction, rather than the four needed with the
labeled-primer approach. This is accomplished by labelling each of the
dideoxynucleotide chain-terminators with a separate fluorescent dye,
which fluoresces at a different wavelength.
This method is easier and quicker than the dye primer approach, but may
produce more uneven data peaks (different heights), due to a template
dependent difference in the incorporation of the large dye
chain-terminators. This problem has been significantly reduced with the
introduction of new enzymes and dyes that minimize incorporation
variability.
This method is now used for the vast majority of sequencing
reactions as it is both simpler and cheaper. The major reason for this
is that the primers do not have to be separately labelled (which can be
a significant expense for a single-use custom primer), although this is
less of a concern with frequently used 'universal' primers.
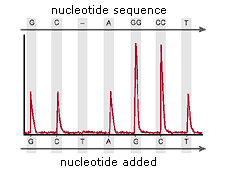
>> 처음 생긴 시퀀싱 방법으로, 많이 알려진 방법이고, 현재 학교에서 배우는게 이 방법이다. chain termination method라고 하여, 이름처럼 중간중간 끊어진 부분을 읽는 것이다. PCR할 때 dNTP와 함께 약간의 ddNTP를 첨가하여 사슬에 ddNTP가 결합하는 부분은 더이상 진행되지 않게 된다. 무작위적으로 ddNTP가 결합하면서 다른 길이의 DNA 사슬이 중합되고, 전기영동을 통해서 분리해내면 길이 순서대로 정렬된다. ddNTP에는 형광 dye가 결합되어 있어서, A T G C 가 염기를 구분할 수 있다. 따라서, 이를 전기영동하고 형광dye를 순서대로 읽으면 해당 DNA의 서열을 알 수 있게 된다. 우리 실험실에 있는 ABI사의 sequencing 장비가 이 원리를 이용한다.
During capillary electrophoresis, the products of the
cycle sequencing reaction are injected electrokinetically into
capillaries filled with polymer. High voltage is applied so that the
negatively charged DNA fragments move through the polymer in the
capillaries toward the positive electrode.
A high voltage is applied so that the negatively
charged DNA fragments move through the polymer in the capillaries
toward the positive electrode (Figure 1). Capillary electrophoresis can
resolve DNA molecules that differ in molecular weight by only one
nucleotide.
Figure 1: Fluorescently labeled DNA fragments move through a capillary
Figure 2: DNA fragments pass through a laser beam and optical detector
Shortly before reaching the positive electrode,
the fluorescently labeled DNA fragments, separated by size, move
through the path of a laser beam. The laser beam causes the dyes on the
fragments to fluoresce. An optical detection device on Applied
Biosystems DNA analyzers detects the fluorescence (Figure 2). The Data
Collection Software converts the fluorescence signal to digital data,
then records the data in a *.ab1 file. Because each dye emits light at
a different wavelength when excited by the laser, all four colors, and
therefore, all four bases, can be detected and distinguished in one
capillary injection.
After electrophoresis, data collection software
creates a sample file of the raw data. Using downstream software
applications, further data analysis is required to translate the
collected color-data images into the corresponding nucleotide bases.
Primary Analysis
These tools convert the images gathered during Data Collection into
all four colors, representing the four corresponding nucleotide bases
(Figure 1). For example, our Sequence Analysis Software is a primary
analysis tool that must be used after collection is completed. The
Sequence Analysis software application allows users to basecall and
re-basecall, trim data ends, display, edit and print sample files.
Primary analysis software processes the your raw data in an *.ab1 file
using algorithms and applies the following analysis settings to the
results:
Basecalling The selected basecaller processes the fluorescence signals,
then assigns a base to each peak (A, C, G, T, or N). If the KB™
basecaller is used, it also provides per-base quality value
predictions, optional mixed base calling, and automatic identification
of failed samples.
Figure 1: Primary Analysis Software results display each of the 4 bases as a different color
Mobility Shift Correction The mobility file compensates for the change in DNA fragment
mobility caused by the dye molecule attached to the DNA fragment and
changes the color designation of bases depending on the type of
chemistry used to label the DNA.
Quality Value (QV) If the KB basecaller is used for analysis, the software
assigns a QV for each base. The QV predicts the probability of a
basecall error. For example, a QV of 20 predicts an error rate of 1%.
The quality prediction algorithm is calibrated to return QVs that
conform to the industry-standard relationship established by the Phred
software. If your pipeline involves analysis with Phred software to
assign QVs after the data is basecalled, you can simplify your workflow
and use the KB basecaller instead. The KB basecaller can perform
basecalling and assign QVs. Then, you can generate *phd.1 or *.scf
files using the KB basecaller to integrate with your downstream
pipeline.
Secondary Analysis
These tools allow you to further refine your results. Algorithms in
our secondary analysis software products perform a number of functions
supporting applications such as mutation detection and genotyping, and
produce graphical outputs.
Pyrosequencing,
which was originally developed by Mostafa Ronaghi, has been
commercialized by Biotage (for low throughput sequencing) and 454 Life
Sciences (for high-throughput sequencing). The latter platform
sequences roughly 100 megabases in a 7-hour run with a single machine.
In the array-based method (commercialized by 454 Life Sciences),
single-stranded DNA is annealed to beads and amplified via emPCR. These DNA-bound beads are then placed into wells on a fiber-optic chip along with enzymes which produce light in the presence of ATP.
When free nucleotides are washed over this chip, light is produced as
ATP is generated when nucleotides join with their complementary base pairs.
Addition of one (or more) nucleotide(s) results in a reaction that
generates a light signal that is recorded by the CCD camera in the
instrument. The signal strength is proportional to the number of
nucleotides, for example, homopolymer stretches, incorporated in a
single nucleotide flow.
>> Pyrosequencing은 최근에 새롭게 등장한 방법이다. 좀 복잡하다.;;; 나도 Sanger 말고 이런 방법도 있다는걸 안게 얼마 안되었다. Sanger sequencing이 한번에 sequencing할 수 있는 길이가 짧아서 게놈 단위의 분석이 어려운데 비해서 이 방법은 하나의 장비에서 단 7시간동안 1억bp나 되는 긴 서열의 분석이 가능하다.
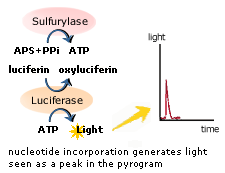
>> Pyrosequencing은 4가지 효소인 DNA polymerase, Sulfurylase, Luciferase, Apyrase등의 Enzyme Cascade를 응용한 것으로 그 원리는 다음과 같다. 우선 Sequencing Primer 가 분석 하려는 DNA 가닥에 결합한다. 그 후 특정의 염기가 반응용액에 떨어지면 DNA 염기 중합반응이 일어나면서 Pyrophosphate(PPi)기가 떨어져 나온다. 이때 Pyrophosphate는 Sulfurylase에 의해 APS(adensosine 5'' phosphosulfate)와 반응하여 ATP를 만들어내고, 이 ATP는 Luciferase를 활성화 하여 Luciferin을 Oxyluciferin으로 산화 시킨다. 이때 Oxyluciferin이 빛을 내게 되며, 이 빛을 CCD camera로 검출하게 되며, 이에 따라 특정 염기를 인식하여 분석을 한다. (출처:(주)BMS 자료)
<Procedeure>
The method is based on detecting the activity of DNA polymerase with a chemiluminescentenzyme. Essentially, the method allows sequencing of a single strand of DNA
by synthesizing the complementary strand along it, one base pair at a
time, and detecting which base was actually added at each step. The
template DNA is immobilized, and solutions of A, C, G, and T nucleotides are added sequentially. Light is produced only when the nucleotide
solution complements the first unpaired base of the template. The
sequence of solutions which produce chemiluminescent signals allows the
determination of the sequence of the template. ssDNA template is hybridized to a sequencing primer and incubated with the enzymes DNA polymerase, ATP sulfurylase, luciferase and apyrase, and with the substrates adenosine 5´ phosphosulfate (APS) and luciferin.
The addition of one of the four deoxynucleotide triphosphates (dNTPs)(in
the case of ATP we add ATPαS which is not a substrate for a luciferase)
initiates the second step. DNA polymerase incorporates the correct,
complementary dNTPs onto the template. This incorporation releases pyrophosphate (PPi) stoichiometrically.
ATP sulfurylase quantitatively converts PPi to ATP
in the presence of adenosine 5´ phosphosulfate. This ATP acts as fuel
to the luciferase-mediated conversion of luciferin to oxyluciferin that generates visible light in amounts that are proportional to the amount
of ATP. The light produced in the luciferase-catalyzed reaction is
detected by a camera and analyzed in a program.
Unincorporated nucleotides and ATP are degraded by the apyrase, and the reaction can restart with another nucleotide.
Currently, a limitation of the method is that the lengths of
individual reads of DNA sequence are in the neighborhood of 300-500
nucleotides, shorter than the 800-1000 obtainable with chain termination methods (e.g. Sanger sequencing). This can make the process of genome assembly more difficult, particularly for sequence containing a large amount of repetitive DNA.
As of 2007, pyrosequencing is most commonly used for resequencing or
sequencing of genomes for which the sequence of a close relative is
already available.
The templates for pyrosequencing can be made both by solid phase
template preparation (Streptavidin coated magnetic beads) and enzymatic
template preparation (Apyrase+Exonuclease).
Y-SNP-genotyping – a new approach in forensic analysis
R. Lessiga, M. Zoledziewskac, K. Fahrb, J. Edelmanna, M. Kostrzewab, T. Doboszc, W.J. Kleemann
Forensic Science International 154 (2005) 128–136
Y-chromosomal DNA polymorphisms, especially Y-STRs are well established in forensic routine case work. The STRs are used for identification in paternity deficiency cases and stain analysis with complicate mixtures of male and female DNA. In contrast, Y-chromosomal SNPs are a new tool in forensic investigations. At present, Y-SNPs are mainly used in molecular anthropology for evolutionary studies. Nevertheless, these markers could also provide very useful information for the analysis of forensic cases. The aim of the presented study was to test Y-SNP-typing for stain analyses using different methods—SNaPshot and MALDI-TOF MS. Both methods are based on the principle of minisequencing. The selected Y-SNP markers are suited to define the most important European haplogroups.
>> Y-STR은 법과학 사건 조사에서 부계 식별 또는 남성과 여성의 DNA가 섞여있을 경우에 유용하게 이용할 수 있다. STR과는 달리, Y-SNP는 법과학 조사에서 새롭게 이용되는 도구이다. 현재는 주로 인류학의 진화 연구에 이용되고 있다. 그렇지만 이들 마커는 이들은 법과학 사건 분석에도 매우 유용한 정보를 제공해 줄 수 있다. 이 연구의 목표는 다른 방법을 사용하여 흔적에 대한 Y-SNP typing 분석방법 두가지(SNaPshot 과 MALDI-TOF MS)를 테스트해보는 것이다. 두 가지 방법은 minisequencing을 기반으로 하고 있다.
==========
* genotyping of Y-SNPs using the genoSNIP assay based on MALDI-TOF MS is less time consuming.
* MALDI-TOF MS is not as widely distributed, the mass spectrometry has the disadvantage of high starting costs so far.
* Y-SNPs correctly also in samples containing less than 125pg DNA.
* High amount of female DNA did not disturb the PCR reaction of the male part.
* detection of the haplogroups can give additional information in the routine of criminalistics to identify an unknown body or perpetrator.
* A special advantage of the SNPs is the very short length of the fragments, what is very important in particular for the analysis of degraded DNA.
미국의 한 생명과학 회사에서 만든 PCR 송 입니다. PCR이란 생물학에서 DNA를 증폭하는 기술인데요. 아는 사람만 이해할 수 있겠지만... 아는 사람만 재밌는 뭐 그런 노래죠ㅋㅋ
The PCR Song
There was a time when to amplify DNA, You had to grow tons and tons of tiny cells.
Then along came a guy named Dr. Kary Mullis, Said you can amplify in vitro just as well.
Just mix your template with a buffer and some primers, Nucleotides and polymerases, too.
Denaturing, annealing, and extending. Well it’s amazing what heating and cooling and heating will do.
PCR, when you need to detect mutations. PCR, when you need to recombine. PCR, when you need to find out who the daddy is. PCR, when you need to solve a crime.